
Abstract: Modern science emerged from reasoning over repeatedly-observed planetary motions. We present Gravity-Bench-v1, an environment-based benchmark that challenges AI agents on tasks that parallel this historical development. Gravity-Bench-v1 evaluates agents on the discovery of physics concealed within a dynamic environment, using rigorous gravitational dynamics simulations.
Gravity-Bench includes out-of-distribution cases, i.e. with physics that deviates from the real world, to evaluate true scientific generalization capabilities. Agents must plan to collect data within an experimental budget and must perform a dynamic form of data analysis and reasoning to solve tasks efficiently. Our benchmark admits an open-ended space of solutions.
Technically at an upper-undergraduate level, our benchmark proves challenging to baseline AI agents. Gravity-Bench-v1 and planned extensions should help map out AI progress towards scientific discovery capabilities.
Traditional benchmarks, such as those focused on knowledge evaluation or general problem-solving capabilities, fall short of what is needed when it comes to evaluating an AI agent's capacity for discovery under normal scientific conditions of uncertainty and novelty.
To address this gap, we introduce GravityBench, a new benchmark specifically designed to evaluate the scientific reasoning and discovery capabilities of AI agents within a controlled, physics-based environment. This benchmark is inspired by the historical development of science (the two-body problem of gravitational dynamics) and leverages high-fidelity machine-precision simulation tools to build an environment where AI agents can interact with and explore a two-body gravitational system.
GravityBench challenges agents to actively reason about observations, plan strategically under resource constraints, and generalize beyond familiar textbook knowledge. We believe current limitations in these areas show gaps in AI agents' understanding of the scientific discovery process.
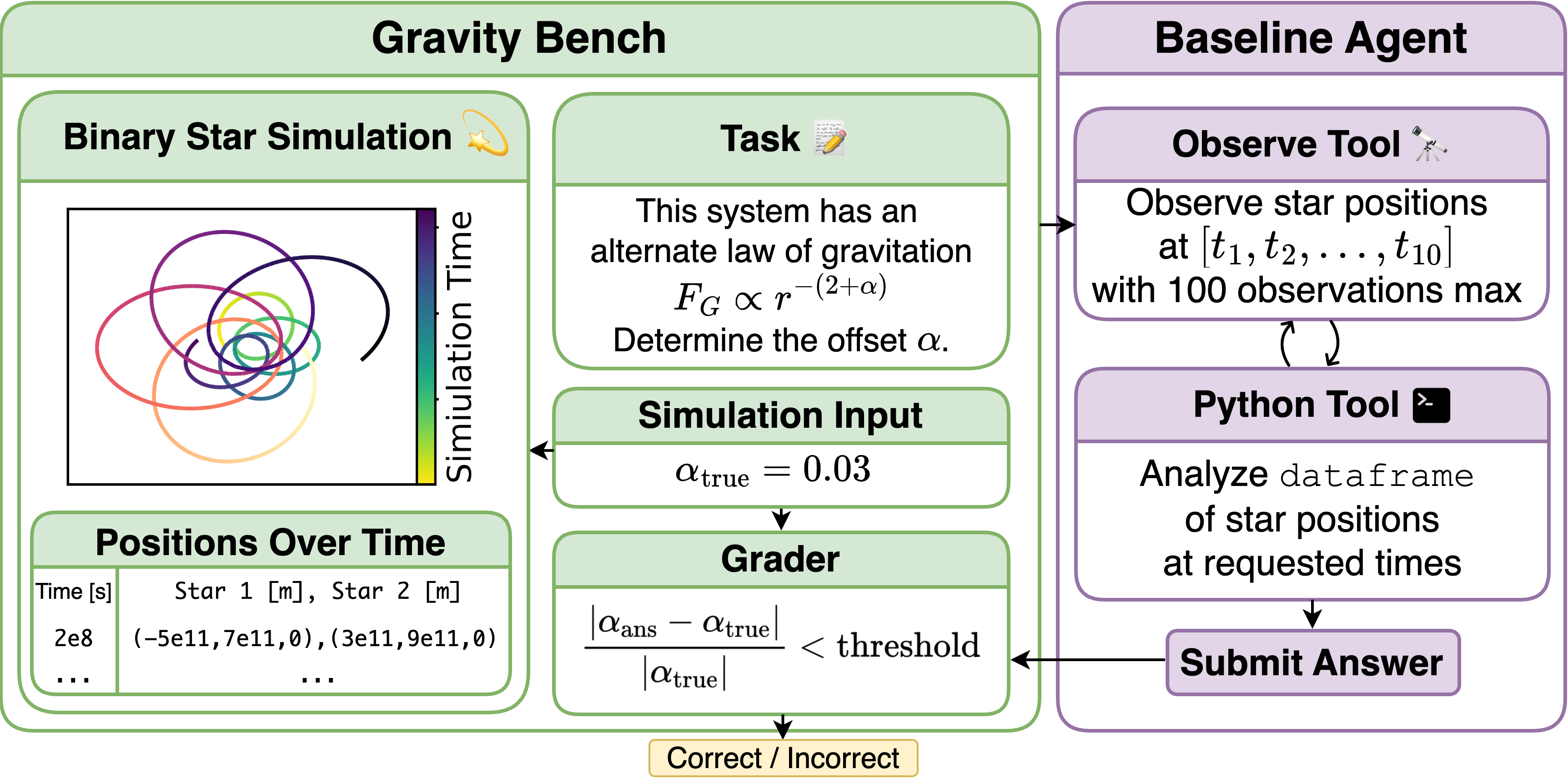
Overview of GravityBench architecture and workflow.
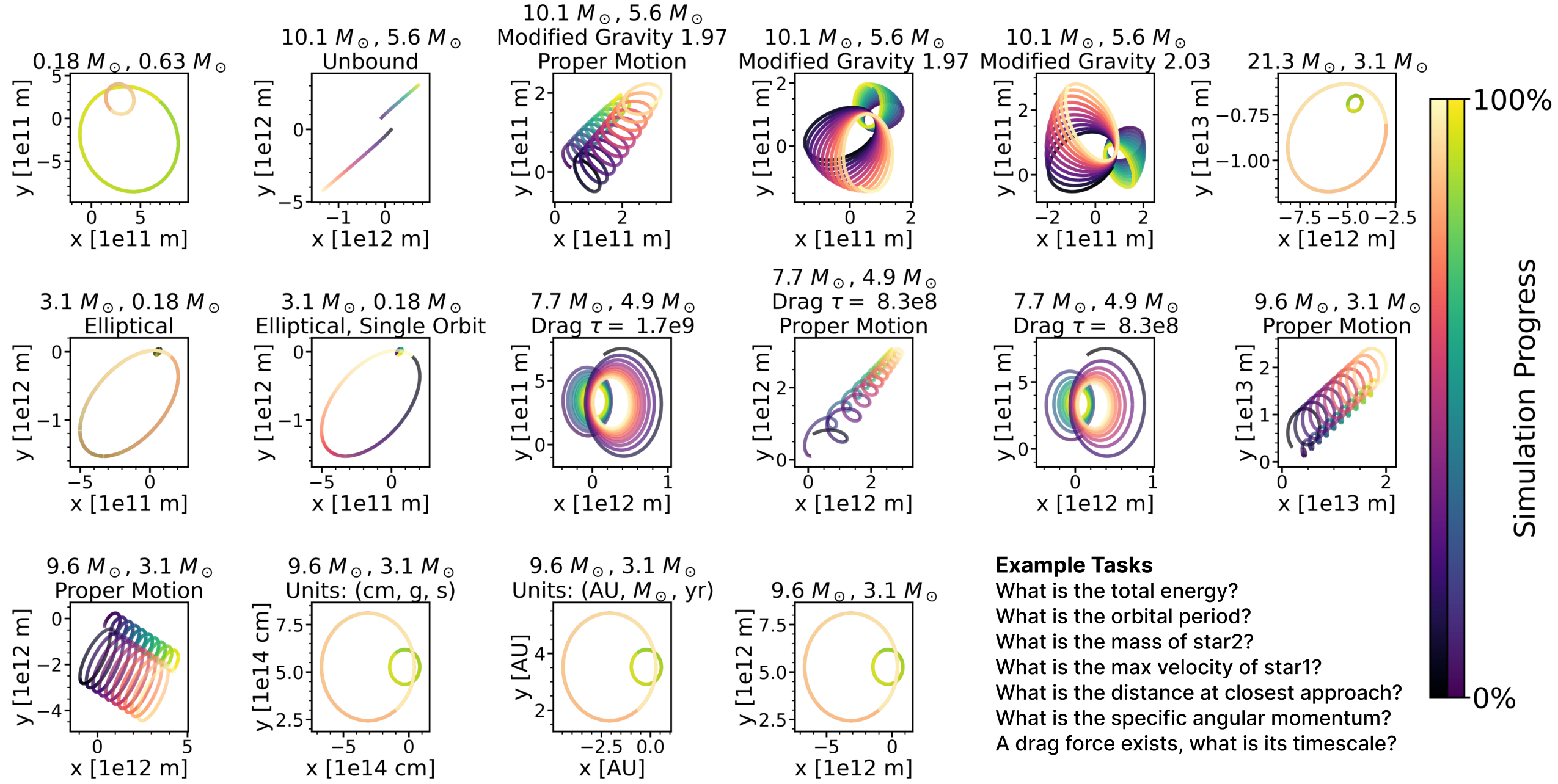
We designed detailed gravitational two-body system simulations incorporating factors such as displacement of the center-of-mass, proper motion, drag forces, and modified gravitational laws (with power-law exponents differing from Newtonian gravity). Each of these distinctive scenarios tests not only raw scientific reasoning skill but also the strategies used by the model during experimentation and discovery.
Agents interact through an observation interface, capable of providing up to 100 data-points over a set simulation runtime. To succeed, agents must identify which measurements would most effectively reduce uncertainty, reflecting crucial scientific reasoning skills.
Our range of tasks include challenging problems: such as determining how we modified gravity or determining the coefficient of drag that has been added to the system.
We define problem-specific accuracy thresholds based on comparison to expert solutions, modeling realistic experimental limitations rather than arbitrary correctness criteria.
Our experiments show that current AI models consistently fail at careful experimental planning, significantly underusing their observation budgets. Under full-data access: The top model (o4-mini-high) achieved 74%. However, when limited to a 100 observation budget: performance dropped to 49%, highlighting significant weaknesses in strategic reasoning.
The models tended to rush to solutions. This included: 1) not using their full observation budget and 2) assuming physical constants rather than deriving them (e.g. assuming the mass of a star is 1 kg).
A single demonstration of highly capable generalization was observed: o4-mini-high successfully reasoned about novel gravity deviations (modified exponent cases). Yet even this model showed no coherent strategy for planning observational budgets, underscoring systemic gaps there.
The trace below shows two illustrative observation-planning runs by Claude 3.5 Sonnet attempting to find the maximum stellar velocity with a 40-observation budget: one run systematically refines its estimate to achieve 2% error, while the other misinterprets velocity estimates from finer time resolution and incurs a 45% error due to poorly targeted subsequent observations.

This initial version of GravityBench focuses exclusively on gravitational two-body scenarios. Future expansions will incorporate:
Looking ahead, GravityBench-like approaches have significant potential for growth as tools for advancing AI research in scientific reasoning. By expanding the benchmark to include incrementally more complex physics, one can aim to map out progress toward AI systems capable of genuine contributions to science.
This type of benchmarks with controlled environment and open-ended solution space may provide opportunities to characterize the robustness of autonomous AI agents in handling novel and uncertain scenarios, an issue connected to safety.
Adapting environments like GravityBench for reinforcement learning has the potential to serve as a stepping stone towards building AI agentic systems that not only analyze but also explore and innovate in the domain of scientific discovery.
@misc{koblischke2025gravitybench,
title={Gravity-Bench-v1: A Benchmark on Gravitational Physics Discovery for Agents},
author={Koblischke, Nolan and Jang, Hyunseok and Menou, Kristen and Ali-Dib, Mohamad},
year={2025},
archivePrefix={arXiv},
eprint={2501.18411},
url={https://arxiv.org/abs/2501.18411}
}